Elasticsearch Pipeline Tutorial
This comprehensive ElasticSearch tutorial focuses on building real world like data pipelines to move data from one system to another. The painless script will run in a elasticsearch pipelines.
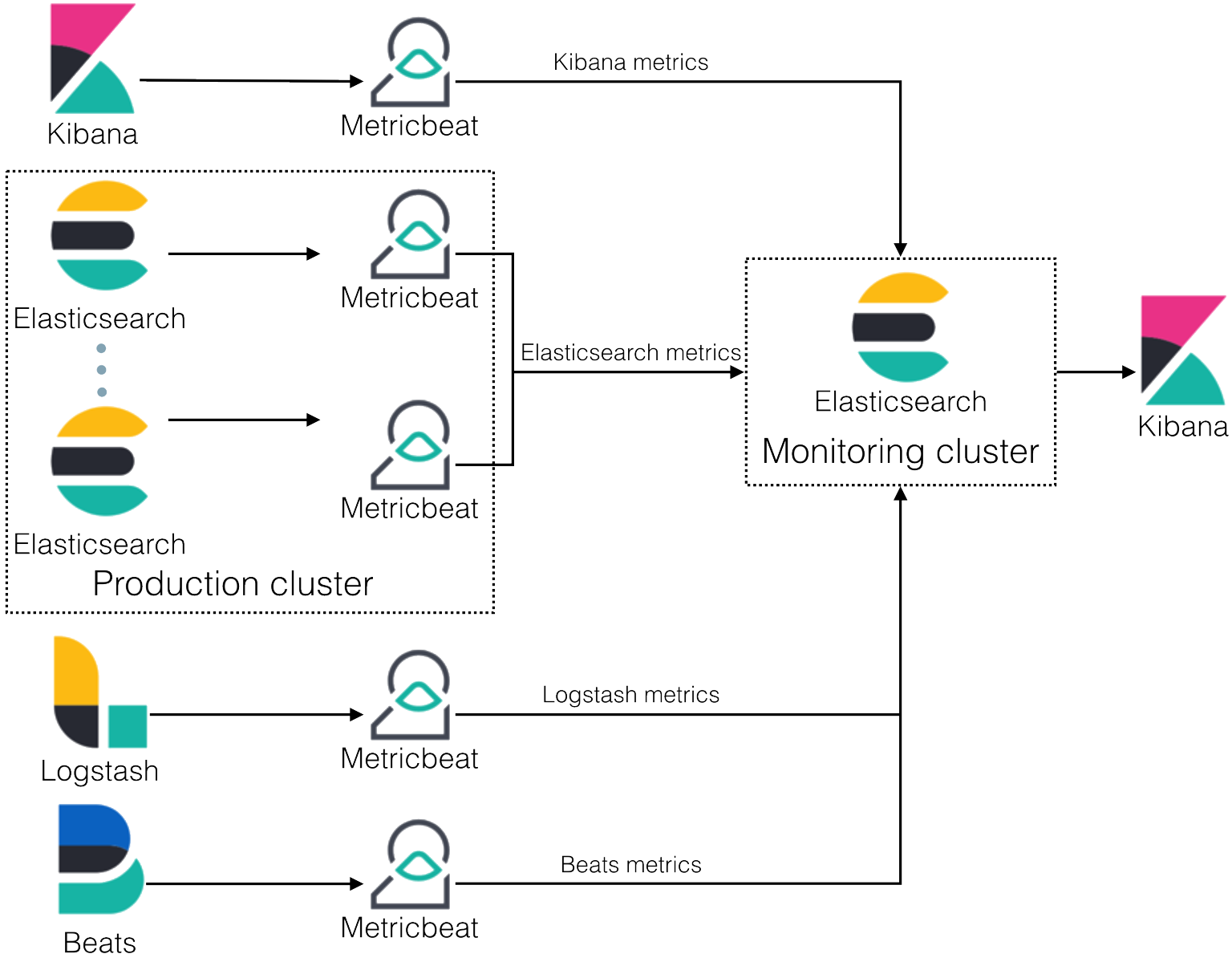
Monitoring Overview Elasticsearch Guide 7 13 Elastic
For more details on Elasticsearch installation and usage take a look at our Elasticsearch tutorial here - Elasticsearch tutorial.

Elasticsearch pipeline tutorial. A Logstash pipeline which is managed centrally can also be created using the Elasticsearch Create Pipeline API which you can find out more about through their documentation. Lets first get some documents that we want to query. Fix field names in tutorial 4 Add latest docstring and tutorial changes Co-authored-by.
Eline remove manual torch install on colab update elasticsearch version everywhere to 792 fix FAQPipeline update tutorials with new pipelines Add latest docstring and tutorial changes revert faqpipeline change. Set to true to make the index and index metadata read only false to allow writes and metadata changes. A common practice for any data engineer.
This problem of ingesting csv logs shipped from filebeats directly into elasticsearch can be solved in many ways. To do this run the following code in Elasticsearch plugin to execute the pipeline - Copy Code Response. Derivatives and cumulative sum aggregation are two common examples of parent pipeline aggregations in Elasticsearch.
K stands for Kibana. Please note that all nodes in elasticsearch are ingest node by default but it can be disabled by adding the configuration in elasticsearchyml file. After pipeline creation the next step is to create a.
To get started go here to download the sample data set logstash-tutorialloggz used in. Elasticsearch will run on port 9200 by default. Fielddata mapping parameter Accessing data in pipelines Most Popular.
Elasticsearch Guide 713 Modifying your data Pipeline definition fielddata mapping parameter Accessing data in pipelines Pipeline definitionedit. The tutorial below shows the detailed actions to configure a successful setup. The pipeline configuration helps the ingest node to pre-process the document and transform the document as per the instructions provided in the pipeline processors.
Haystack provides a customizable pipeline for. When you continuously index timestamped documents into Elasticsearch you typically use a data stream so you can periodically roll over to a new index. It takes the values of this aggregation and computes new buckets or aggregations adding them to buckets that already exist.
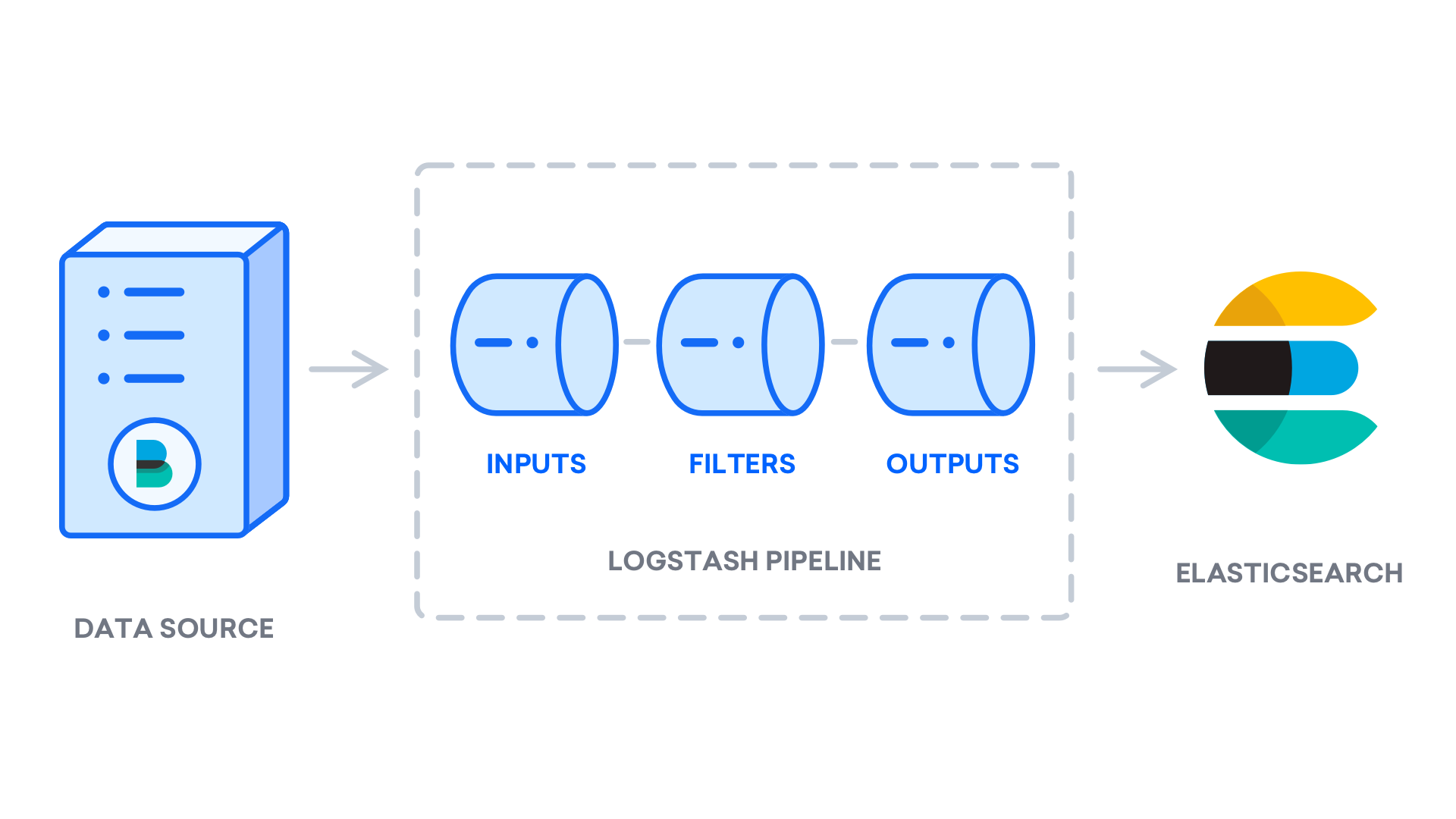
Used for both shipping as well as processing and storing logs. Logstash is like a pipeline tool that is used for collecting data from multiple sources. If you get the same response as the below output the code is executed successfully.
In this tutorial on indexing csv files using Elasticsearch pipelines we will use painless script ingest a csv file. ElasticSearch LogStash and Kibana are all developed managed and maintained by the company named Elastic. This elasticsearch tutorial course will provide numerous elasticsearch.
It is often called as a data pipeline for Elasticsearch. Is a visualization tool a web interface which is hosted through Nginx or Apache. ELK Stack is designed to allow.
Lets take a quick look at the different components that we will be using throughout this blog post. A parent pipeline aggregation works with the output of its parent aggregation. In this post we are going to cover replicating and transforming travel-samples landmark dataset from Couchbase to Elasticsearch using Elasticsearch connector and an Elasticsearch Ingest node pipeline.
Automate rollover with ILMedit. The API can similarly be used to update a pipeline which already exists. Lets create a Logstash pipeline that takes Apache web logs as input parses those logs to create specific named fields from the logs and writes the parsed data to an Elasticsearch cluster.
This enables you to implement a hot-warm-cold architecture to meet your performance requirements for your newest data control costs over time enforce. In a previous tutorial we discussed the structure of Elasticsearch pipeline aggregations and walked you through setting up several common pipelines such as derivatives cumulative sums and avg bucket aggregations. L stands for LogStash.
E stands for ElasticSearch. - converting files into texts - cleaning texts - splitting texts - writing them to a Document Store In this tutorial we download Wikipedia articles on Game of Thrones apply a basic cleaning function and index them in Elasticsearch. Get Started with Elasticsearch.
Used for storing logs.
From Scratch To Search Playing With Your Data Elasticsearch Ingest Pipelines By Stanislav Prihoda Towards Data Science
How To Install Elasticsearch Logstash And Kibana Elastic Stack On Ubuntu 20 04 Digitalocean

Ingest Pipelines Elasticsearch Guide Master Elastic
Image Result For Elastic Stack Mapping Data Analytics Map Elastic



Comments
Post a Comment